Creating Stack
Fast stack reads a pre-stack seismic dataset and sums (stacks) all input traces belonging to each CMP bin into a single output trace per bin. The result is a post-stack section or volume written directly to a .gsd file on disk. Because the module accumulates partial sums bin-by-bin as it reads data in large sequential chunks, it avoids loading the entire dataset into memory and is therefore well suited to large 3D surveys. An optional NMO correction can be applied on the fly before stacking, and a built-in preprocessing sub-chain allows additional trace conditioning steps to be executed within the same module before the stack is formed.
![]()
![]()
Fast stack module is useful to create the stack quickly. This module doesn't require the data to be sorted. For 2D & 3D dataset, it requires input data set & velocity model. If any additional processing is required, it can be performed within the sub-sequence procedure.
![]()
![]()
Input DataItem
Input SEG-Y data handle - connect/reference to the Output SEG-Y data handle. Input data should be either a NMO corrected data or a NON-NMO corrected data.
Input trace headers - connect/reference to the Output trace headers of the input data.
Use trace vector on disk - By default, FALSE (Unchecked). This option is useful when the input data size is large. This option is used in combination with "Open seismic traces" module.
When unchecked (the default), the module reads traces from a standard SEG-Y file via the connected SEG-Y handle and sorted trace index. When checked, it switches to an on-disk TVOD (Trace Vector On Disk) source, which stores the sorted trace geometry in a companion file so that traces can be retrieved without keeping the full index in RAM. Enable this option for very large 3D datasets that cannot comfortably fit their trace headers in memory. When enabled, connect the "Input traces data handle" TVOD connector instead of the standard SEG-Y and trace-vector connectors.
Input traces data handle - connect/reference to Output traces data handle.
Apply NMO - By default, FALSE (Unchecked). If the input data is NON-NMO corrected data then the user should apply NMO.
Enable this checkbox when the input pre-stack data has not yet been NMO-corrected. The module will apply moveout correction to each gather using the connected VRMS velocity model before stacking, so that reflections align correctly across offsets. When Apply NMO is checked, the VRMS model connector and the NMO parameter group become active. Leave this option unchecked if the data is already NMO-corrected or if you are stacking a common-offset dataset where no moveout correction is required.
Apply NMO - true - If Apply NMO is TRUE (Checked), provide Vrms model.
Vrms model - connect/reference to Vrms model.
![]()
![]()
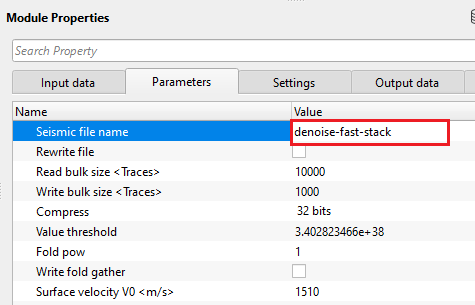
Seismic file name - provide the output file name.
Specify the path and filename for the output stacked section. The file is saved in gNavigator's internal .gsd format. The output will contain one trace per CMP bin, with the same sample interval and domain (time or depth) as the input data. If the Write fold gather option is also enabled, a companion fold file with the suffix "_fold" is automatically created alongside the stack file in the same storage location.
Rewrite file - By default, FALSE (Unchecked). If TRUE (Checked), it overwrites the output file name.
When unchecked (default), the module will raise an error if the output file already exists, protecting existing results from accidental overwriting. Enable this option to allow the module to overwrite the output file each time the workflow is executed. This is useful during iterative parameter testing when you want to replace a previous stack with updated results.
Read bulk size - specify the number of traces to be read as a bulk. By default, 10000
Controls how many traces are read from the input file in a single I/O operation. The default value of 10,000 traces is suitable for most surveys. Increasing this value can improve throughput on systems with fast storage but will increase memory consumption. Decreasing it can help on machines with limited RAM or slow random-access disks. This parameter does not affect the output stack quality; it is purely an I/O performance tuning setting.
Write bulk size - specify the number of traces to be written in a bulk. By default, 1000.
Defines how many stacked output traces are grouped together before being written to the output file. The module accumulates partial stacking results for bins within each write group, then flushes the completed group to disk as a single write operation. The default of 1,000 traces balances write efficiency against memory usage. Larger values reduce the number of write operations and may improve performance on spinning-disk storage, but require more memory to hold the accumulation buffers.
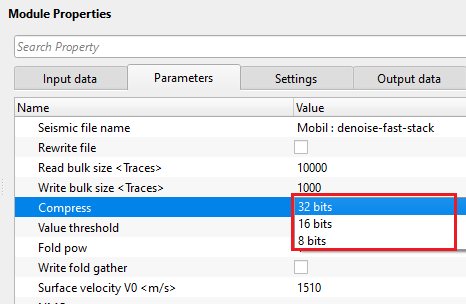
Compress { 32 bits, 16 bits, 8 bits } - this options allows the user to compress the output file size to save the output file size. There are 3 different compressions are available from the drop down menu. By default, 32 bits.
Controls the numeric precision used when writing each sample in the output file. 32 bits (default) stores each sample as a full 32-bit float, preserving the full amplitude dynamic range. 16 bits halves the file size at the cost of reduced amplitude precision, acceptable for most display and interpretation uses. 8 bits produces the smallest file but significantly limits the dynamic range and is generally suitable only for quick QC previews. Use 32 bits for any stack that will be used for quantitative analysis or further processing.
Value threshold - this relates to the stacking process. Keep the default value as it is.
Sets the maximum absolute amplitude value that an individual trace sample is allowed to contribute to the stack. The default is the maximum possible floating-point value (effectively no limit). When individual traces contain anomalously large spike amplitudes caused by noise or data errors, you can set a finite threshold here to exclude those spikes from the stack sum. Any sample whose absolute value exceeds this threshold is treated as zero during accumulation. In most cases the default is appropriate; use this parameter only if your data contains known amplitude outliers that are corrupting the stack.
Fold pow - By default, 1. Fold power is a stacking weight function that uses number of contribution traces as an exponent to enhance or control the influence of stacking.
After all input traces are summed for each bin, the accumulated amplitude is divided by the fold raised to this power. This controls how the stacking normalization responds to variations in fold across the survey. The slider range is 0 to 1 (adjusted as a percentage in the UI). A value of 1 (default) applies standard fold normalization, giving the arithmetic mean of all contributing traces. Values less than 1 boost the contribution of high-fold areas relative to low-fold areas, while the existing notes below explain the per-sample effect in more detail. Leaving the default value of 1 is recommended for most standard stacking workflows.
Fold power = 1; means normal stacking where all the folds are considered
Fold power > 1; means higher fold areas are down weighted
Fold power < 1; means higher fold areas are emphasized.
Write fold gather - By default, FALSE (Unchecked). If TRUE (Checked), it will output Fold gather along with the seismic gather.
When enabled, the module creates a second output file alongside the stack. Each sample in this fold file records the number of input traces that contributed a non-zero value at that time sample for that bin. This fold map is useful for quality control — it lets you verify that survey coverage is uniform and identify bins with insufficient fold that may produce unreliable stacked amplitudes. The fold file is named automatically by appending "_fold" to the output stack filename.
Surface velocity V0 - specify the surface velocity. By default, 1800 m/s.
The near-surface replacement velocity (V0) used for datum correction when the Shift to/from constant datum option is active. This value represents the velocity of the weathering layer or the velocity at the acquisition surface, in m/s. The default of 1,800 m/s is appropriate for many land surveys. Set this to the actual near-surface velocity at your survey location. This parameter has no effect when datum shifting is disabled.
NMO - this section deals with the NMO application.
Stretching parameters - specify the NMO stretching parameters.
This group controls how the NMO operator handles the low-frequency stretch effect that occurs at large offsets and shallow times. NMO stretching causes reflections at far offsets to be shifted by more than those at near offsets, which, if uncorrected, can degrade stack resolution and introduce shallow low-frequency noise into the final stack.
Stretch factor - this parameter determines the NMO stretch factor. By default 100%. Once the user executes the Fast Stack module with the updated Stretch factor then the stack will be created using user defined NMO stretch factor.
The NMO stretch factor defines the maximum allowable relative time shift (as a percentage) that the NMO correction may apply to any sample. The default value of 100% (stored internally as 1 in the source) effectively disables stretch-based muting — all samples are corrected regardless of how much they stretch. Reducing this value (for example, to 50%) will mute samples in the far-offset region of shallow reflectors where the NMO correction would cause excessive stretching. This is active only when Use stretch limiting is enabled. For standard stacking workflows, the default is appropriate.
Smoothing parameter Y velocity - Default value is 10. Define the number of vertical samples to define the velocity smoothing.
Specifies the number of time samples over which the velocity model is smoothed in the vertical (time) direction before applying NMO. Default is 10 samples. Smoothing reduces rapid vertical velocity fluctuations that could cause instability or ringing in the NMO-corrected traces. Increase this value if the velocity model has short-period oscillations that produce artefacts in the corrected gathers. Decrease it if fine vertical velocity resolution is important and the model is known to be stable.
Use stretch limiting - By default, FALSE (Unchecked). It will limit the % stretch factor.
When enabled, the NMO correction applies a stretch mute: any sample in the corrected trace that would require a time shift exceeding the Stretch factor percentage of its original two-way time is zeroed out. This prevents the characteristic NMO stretching of shallow far-offset events from contaminating the stack. Enable this option when shallow reflection quality is important and you observe strong low-frequency noise in the far-offset part of your gathers. The Stretch factor parameter defines the mute threshold percentage.
Shift data - We can shift the data to final datum or keep it as it is (at topography). As we mentioned earlier, in g-Platform, we estimate velocities from the topography level. In Binning 2D module, we provided created a smoothing topography which is representation of the floating datum. Here we are smoothing the CMP elevations only. The source and receiver elevations remain same:
Shift to/from constant datum - By default, FALSE (Unchecked). If user would like to shift the data to datum then we need to check this option and provide Datum value.
When enabled, the NMO correction includes a datum shift that moves the data from the floating datum (topography surface) to a constant reference elevation. This is useful in land surveys where elevation variations across the line would otherwise degrade stack coherence. When enabled, you must specify the target datum elevation using the Datum parameter, and provide the near-surface replacement velocity in the Surface velocity V0 field. Leave this option unchecked if the data is already referenced to a constant datum or if datum corrections will be applied as a separate static step.
Datum - specify the datum value.
The target elevation for the datum correction, in metres. When the Shift to/from constant datum option is enabled, the NMO correction shifts the data so that time zero corresponds to this constant elevation level. For land surveys, this is typically set to the final datum elevation used in the processing project (for example, sea level or a defined flat reference surface). The datum value must be consistent with the elevation values stored in the trace headers and with the Surface velocity V0 value used for the shift calculation.
GUI - this options is purely for Graphical User Interface. The user can check which inline and/or crossline to output etc.
This group contains interactive preview controls that allow you to inspect a single CMP gather in the module's vista display before and after preprocessing, without running the full stack. Set the inline and crossline coordinates of the bin you want to view, choose the trace sort order, and click the Update current bin gather action to refresh the display. These controls have no effect on the final stacked output.
Current inline - specify the current inline to write as an output
Current crossline - specify the current crossline to write as an output.
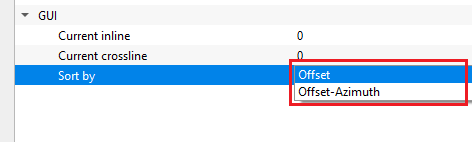
Sort by { Offset, Offset-Azimuth } - this option allows the user to sort the input data either by offset or Offset & Azimuth. Select the options from the drop down menu.
Offset - sorts the data in offset
Offset - Azimuth - sorts the data in offset - azimuth order.
![]()
![]()
Auto-connection - By default, TRUE(Checked).It will automatically connects to the next module. To avoid auto-connect, the user should uncheck this option.
Distributed execution - if enabled: calculation is on coalition server (distribution mode/parallel calculations).
When enabled, the stacking computation is distributed across multiple nodes of a gNavigator coalition server cluster. The input data is divided into bulk chunks that are sent to remote worker nodes for processing; the stacked partial results are collected back at the master node and written to the output file. This is particularly beneficial for very large 3D datasets where single-machine processing would be too slow. Configure the Bulk size, thread limits, job suffix, and optional scripts using the sub-parameters in this group.
Bulk size - chunk size is RAM in megabytes that is required for each machine on the server (find this information in the Information, also need to click on action menu button for getting this statistics):
Limit number of threads on nodes - limit numbers of of threads on nodes for performing calculations.
Job suffix - add a job suffix.
Set custom affinity - an axillary option to set user defined affinity if necessary.
Affinity - add your affinity to recognize you workflow in the server QC interface.
Number of threads - One less than total no of nodes/threads to execute a job in multi-thread mode. Limit number of threads on main machine.
Run scripts - it is possible to use user's scripts for execution any additional commands before and after workflow execution
Script before run - path to ssh file and its name that will be executed before workflow calculation. For example, it can be a script that switch on and switch off remote server nodes (on Cloud).
Script after run - path to ssh file and its name that will be executed before workflow calculation.
Skip - By default, FALSE(Unchecked). This option helps to bypass the module from the workflow.
![]()
![]()
Current gather before preprocessing -
Vista display showing the CMP gather selected by the GUI inline and crossline controls, sorted by offset (or offset-azimuth), after NMO correction but before any preprocessing sub-chain steps have been applied. Use this display to verify that the NMO correction is properly aligning reflections across offsets. Updated by the Update current bin gather action.
Current gather after preprocessing -
Vista display showing the same CMP gather after all preprocessing sub-chain steps have been applied. Compare this with the "before preprocessing" display to verify that the preprocessing steps are having the intended effect on the gather. This gather represents exactly what will be summed to form the stacked trace for this bin. Updated by the Update current bin gather action.
The example below demonstrates a typical Fast stack workflow for creating a post-stack section from pre-stack CMP-sorted data without first sorting the data into a separate gather file.
![]()
![]()
In this example workflow, we discuss about how to create a stack section without sorting the data.
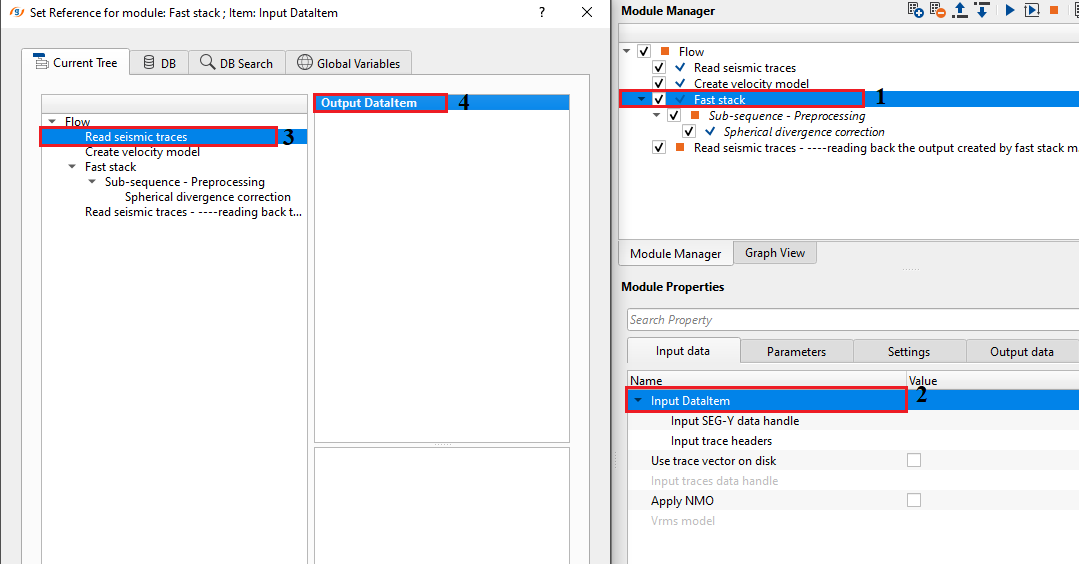
We need to apply NMO correction to the input gathers as the input gathers are NON-NMO corrected gathers. So Check "Apply NMO" option and connect/reference the Vrms model to Velocity model from Create Velocity model module.
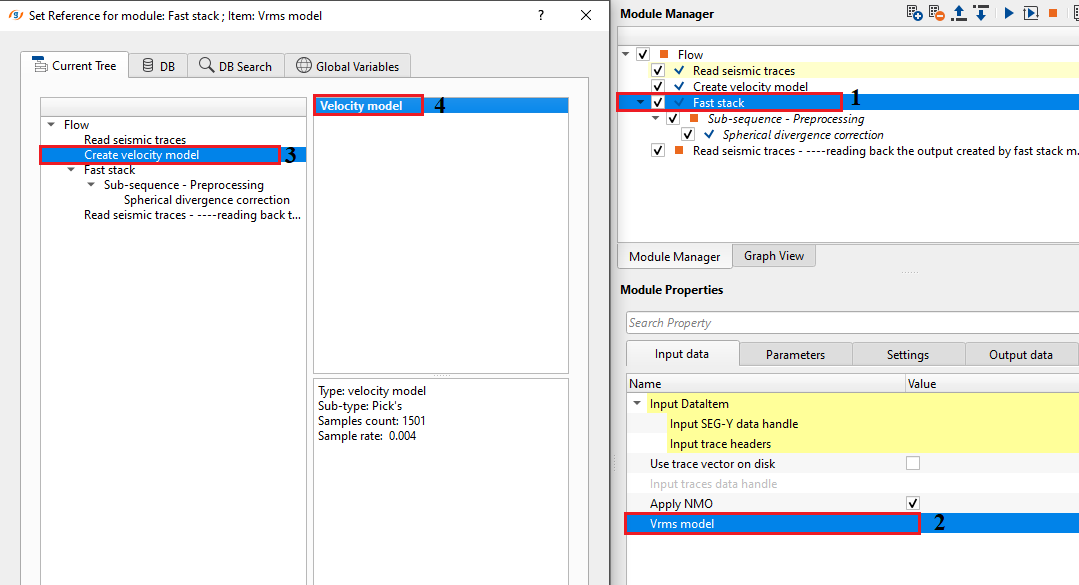
Set up the parameters according to the input and user requirements (like shifting the datum to datum or selecting a particular inline/crossline etc.)and execute the module.
In case the user wants to apply additional processing procedures/step, it can be implemented by adding additional processing module inside the sub-sequence procedure. This helps in avoiding additional processing procedures like band pass filtering, despiking, AGC, spherical divergence correction etc.
It will not display the final stack output as a vista item. In order to view the output, the user MUST read it back by using "Read seismic traces" module and change the parameter of "Load data to RAM from No to YES".
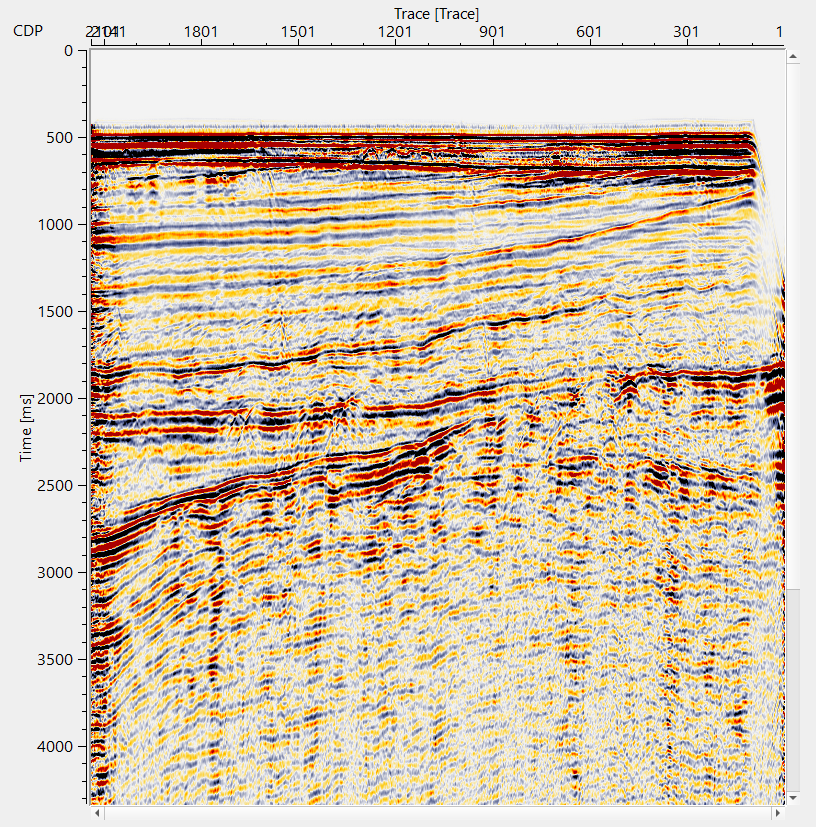
![]()
![]()
Update current bin gather - This action refreshes the gather preview for the bin specified by the Current inline and Current crossline GUI controls.
Click this button to read the pre-stack gather for the currently selected bin, apply NMO correction (if enabled), and run it through the preprocessing sub-chain. The result is shown in both the "Current gather before preprocessing" and "Current gather after preprocessing" vista panels. This is a preview-only action — it does not write any output to disk. Use it to check NMO alignment and preprocessing quality on a representative bin before executing the full stack calculation.
![]()
![]()
YouTube video lesson, click here to open [VIDEO IN PROCESS...]
![]()
![]()
Yilmaz. O., 1987, Seismic data processing: Society of Exploration Geophysicist
 * * * If you have any questions, please send an e-mail to: support@geomage.com * * *
* * * If you have any questions, please send an e-mail to: support@geomage.com * * *