Reading multiple 2D post stack SEG-Y files
![]()
![]()
Seismic data is written/stored in the tapes/disks in an orderly manner to retrieve it back. The input data may be recorded in different formats like RODE, SEG-2, SEG-D or SEG-Y. Modern seismic data is most commonly written in SEG-D or SEG-Y. To read this seismic data, we use SEG-Y reader to look into the content of the seismic data.
Read multi SEG-Y traces module is used to read multiple 2D post-stack data. From this, we get individual output gathers or we can combine all the input gathers into a single output gather by using Save multi SEG-Y module.
![]()
![]()
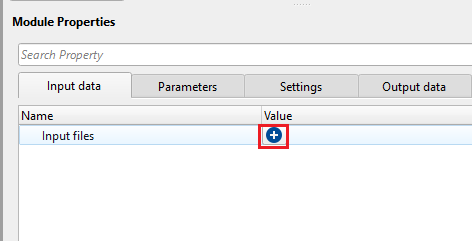
Input files - provide the path and file name of the input SEG-Y files.
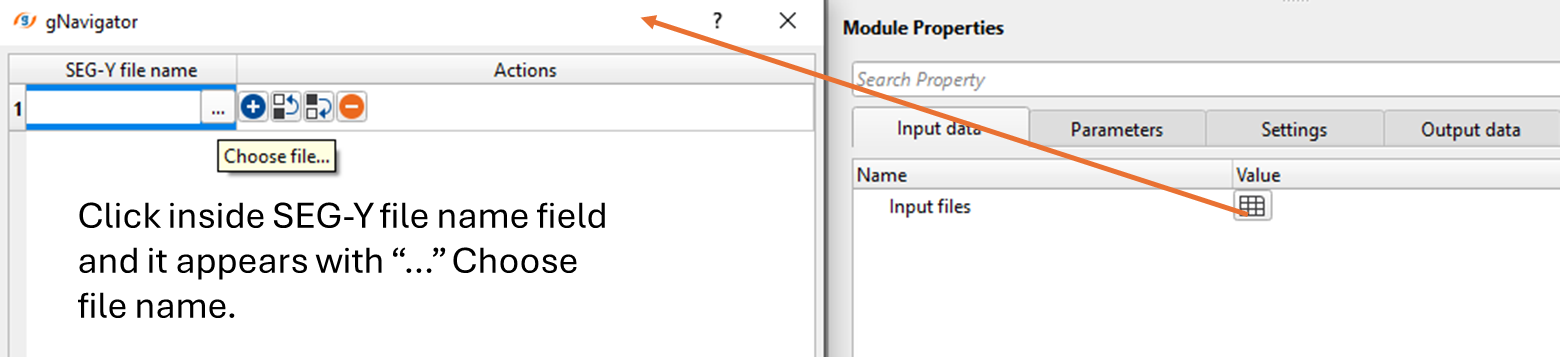
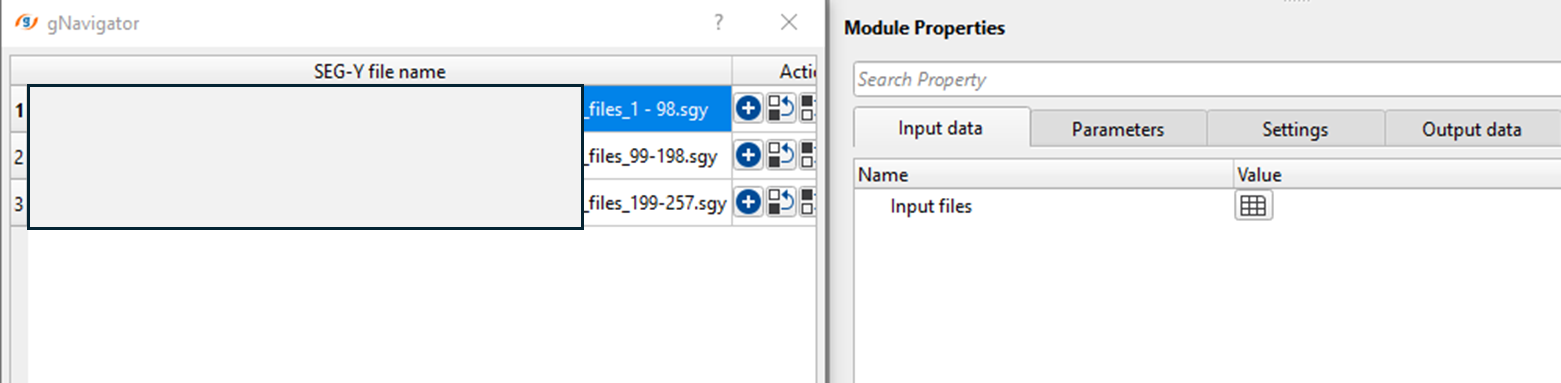
Click on ![]() icon and it will pop-up a window. Click inside the 1st row. Browse through the folder and provide the input SEG-Y files. To select multiple files, hold Shift and select all files.
icon and it will pop-up a window. Click inside the 1st row. Browse through the folder and provide the input SEG-Y files. To select multiple files, hold Shift and select all files.
![]()
![]()
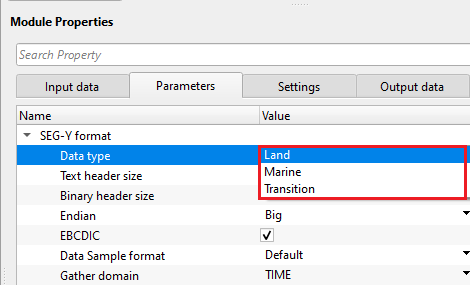
SEG-Y format - This section deals with the basic SEGY format details like type of data i.e. land/marine/transition, EBCDIC, binary headers information etc.
Data type - specify the input data type from the drop down menu. There are 3 types available. Land, Marine, Transition.
Text header size - text header stores the survey and processing history information. This is in ASCII format. The default size is 3200 bytes. This is also known as EBCDIC header. The standard size of the text header is 40 rows and 80 columns.
Binary header size - this header stores the data in binary format. Default size is 400 bytes. In this header, we get sample interval, no of samples, measurement system, data format (IBM, floating point, ....) etc. information is stored.
Endian - it refers to the byte order in which a computer stores the multi byte (integers, floating point etc) data in memory or files.
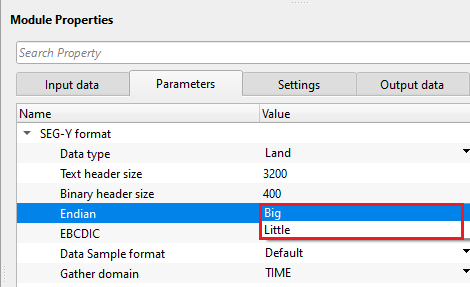
Big Endian - Most Significant Byte is stored at Lowest memory address. Most old computers used Big Endian.
Little Endian - Least Significant Byte is stored at Lowest memory address. Modern computes uses Little Endian.
EBCDIC - displays the EBCDIC/text header if this option is TRUE (Checked). By default, TRUE (Checked).
Data sample format - it represents the seismic trace amplitudes in binary format. It defined in 25-26 byte location of SEG-Y binary header. By default, IEEE (most modern systems uses this). Incorrect data sample format leads to wrong amplitudes, clipping of high/low amplitudes etc. It is also important that both data sample format and Endian type are accurate and correct.
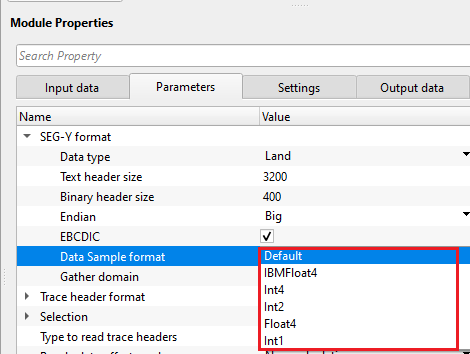
Default - IEEE format
IBMFloat4 - IBM 32 bit Floating point with 4 Bytes as sample size. Most legacy SEGY data is in this format.
Int4 - 32 bit Integer point with 4 Bytes as sample size.
Int2 - 16 bit Integer point with 2 Bytes as sample size.
Float4 - IEEE 32 bit Floating point with 4 Bytes as sample size. Modern SEGY data is in this format.
Int1 - 8 bit Integer point with 1 Byte as sample size.
How to check the correct data sample format?
Go to byte 25-26 byte location of SEG-Y binary header and look for the format IDs.
IBM Float - 1
IEEE Float - 5
Gather domain - allows the user to specify the input data domain type. By default, Time. There are additional domain options available from the drop down menu.
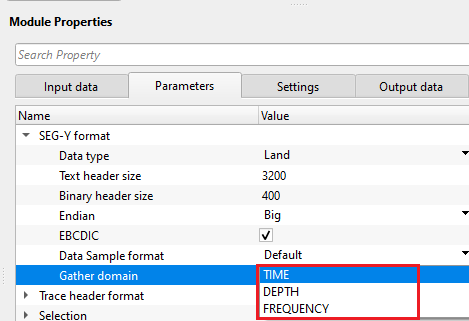
Time - Input data is in Time domain
Depth - Input data is in Depth domain
Frequency - Input data is in Frequency domain
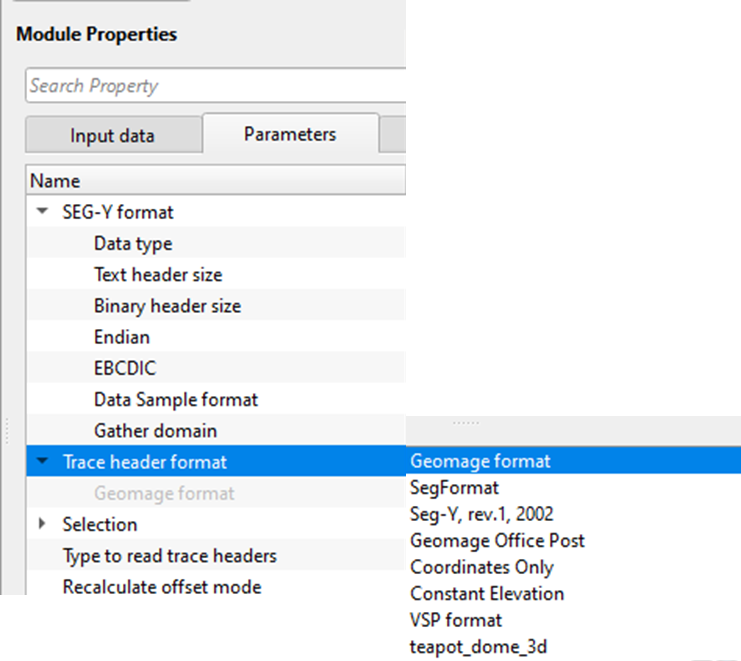
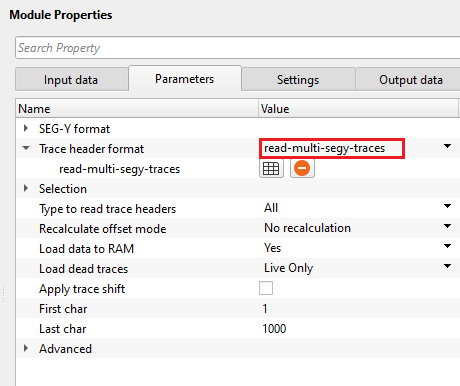
Trace header format - it contains meta data of the seismic trace which means all the parameters like source point, FFID, channel number, source and receiver coordinates etc., are stored at certain byte locations. This is very crucial while reading the SEG-Y data. Make sure that the trace headers mapped correctly to their respective byte locations with correct format.
By default, Geomage format. This is a standard SEG-Y rev 1.0 format.
Selection - this allows the user to specify the azimuth and line length information of the 2D lines
Azimuth from - specify the starting azimuth to be considered. By default, 0.
Azimuth to - specify the maximum azimuth. By default, 180.
Minimum length (2D) - specify the minimum line length of the 2D line.
Maximum length (2D) - specify the maximum line length of the 2D line.
Type to read trace headers { All, First N, Each N } - specify to read all traces or first trace of each gather or each gather. By default, All. It reads all the traces.
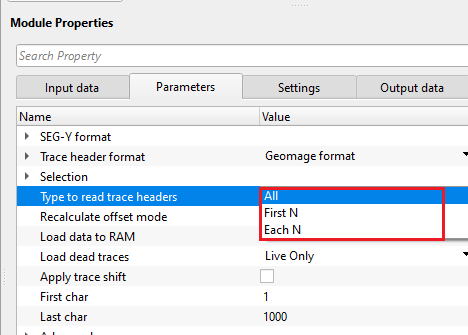
Recalculate offset mode { No recalculation, Recalculate as 2D, Recalculate as 3D } - this allows to recalculate the offsets by using the source and receiver coordinate values. By default, No recalculation.
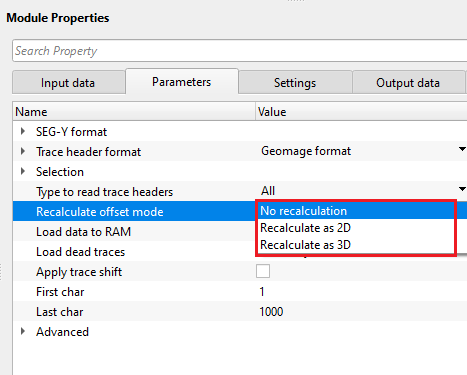
No recalculation - It won't calculate the offsets
Recalculate as 2D - It takes the source and receiver x,y coordinate values and calculates the offset
Recalculate as 3D - It is applicable to the 3D dataset. Similar to 2D, it computes the offsets by using source and receiver x,y coordinates.
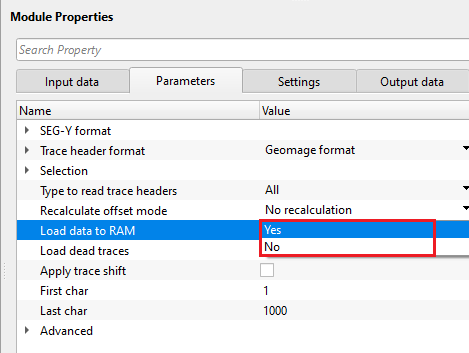
Load data to RAM { Yes, No } - this allows the input data to be displayed as Output. By default, NO. To display the entire input dataset, Load data to RAM as YES.
![]() We recommend NOT to use YES option if the input data size is too big.
We recommend NOT to use YES option if the input data size is too big.
Load dead traces { All traces. Mute dead traces, Live Only, Dead Only, All traces } - this allows the user to decide what kind of traces to be read. Seismic traces have a trace identification number in their trace headers. Based on this, it'll decide whether to read all traces or leave the dead traces.
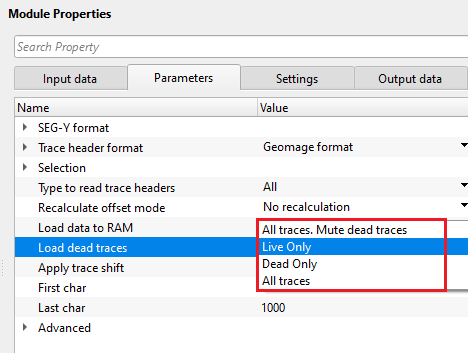
All traces, Mute dead traces - reads all the input traces but mutes/deletes the traces with a trace identification as dead (2)
Live only - reads traces with a trace identification as live (usually 1). By default, Live only.
Dead only - reads Dead traces with trace identification as Dead (2)
All traces - reads all the input traces
Apply trace shift - this allows to apply trace shift to each trace if any trace shift value is stored in the trace headers. By default, FALSE (Unchecked).
First char - specify the starting character position of the output gather name.
Last char - specify the last character position to be considered for the output gather name.
Advanced - this deals with additional parameters which are not mandatory however it is important to pay attention to some of the parameters like Datum etc.
Number of traces - total number of traces to be read as a bulk. By default 100000
Distance for merging points - determines the distance where various source\receiver points will be merged to one point. By default, 0.1 meters.
Apply weight - If this check box is checked, then amplitude weight written in trace header will be used for each trace.
Data datum { Datum trace header, Topography, Constant datum } - choose the correct datum type while reading the data. In case, input data(post stack) having datum information in the trace headers, read the datum from datum trace header.
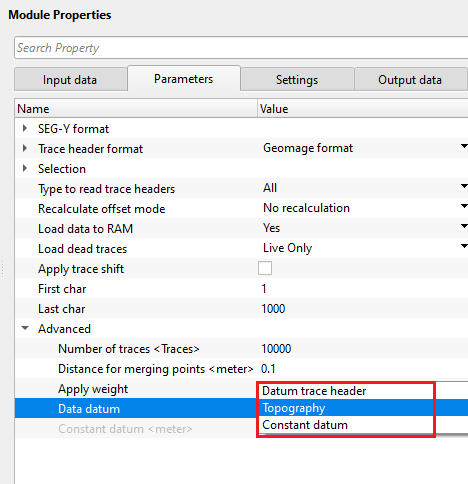
Datum trace header - it takes the datum values from the input trace headers
Topography - reads the input data from the topography level
Constant datum - assigns a constant datum value to the input trace headers. Specify a constant datum value.
DatumMode - Constant datum - specify the constant datum value.
Constant datum - specify the constant datum value.
![]()
![]()
Skip - By default, FALSE(Unchecked). This option helps to bypass the module from the workflow.
![]()
![]()
Output DataItem - this generates the output data items that will be used as a reference/connection for the next modules which are going to be used in the workflow.
Output SEG-Y data handle - generates the Output SEG-Y data handle that will be used as a connection/reference to Input SEG-Y data handle.
Output trace headers - generates Output trace headers that can be set as a reference to Input trace headers.
Output gather - generates Output gather if the Load data to RAM is YES. In that case, this can be set as reference to Input gather.
Output stack line - generates output stack line.
Output crooked line - generates crooked line
Output bin grid - outputs bin grid
Output sorted headers - outputs default sorted headers however these sorted headers can't be used as a sorted headers for subsequent processing.
Output gathers - generates individual output gathers which can be used as connection/reference for the next modules. It is having Gather & Name options. If there are 30 input files then there will be 30 output gathers.
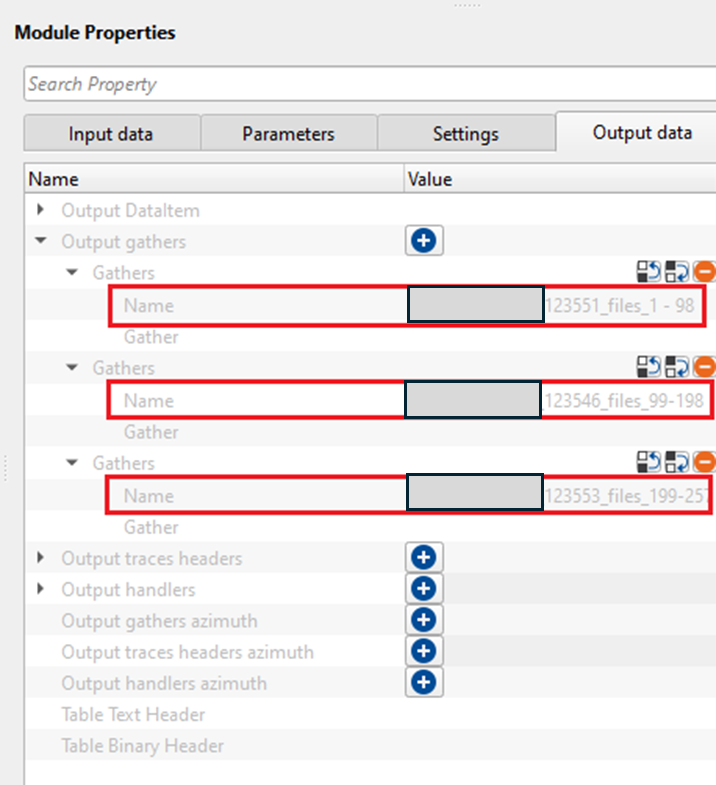
Name - displays the input gather name created by the user defined 1st & last characters.
Gather - Output gather used for reference/connect to the next module
Output traces headers -
Name - displays the input gather name created by the user defined 1st & last characters.
Trace headers - Output trace headers used for reference/connect to the next module
Output handlers -
Name - displays the input gather name created by the user defined 1st & last characters.
Data handlers - Output data handler used for reference/connect to the next module
Output gathers azimuth -
Output traces headers azimuth -
Output handlers azimuth -
Table Text Header - outputs the table text header as a vista item for visual QC.
Table Binary Header - outputs binary header as a vista item. This table can be exported by using "Export table" module.
Number of files - provides information about total number of files
Trace vector size(traces) - provides information of total number of traces
Number of sources - displays total number of sources present in all SEGY files
Number of receivers - displays total number of receivers present in all SEGY files
Number of CMP - displays total number of cmp/cdp/bins present in all SEGY files
Trace vector size (MB) - provides size of an individual trace vector
![]()
![]()
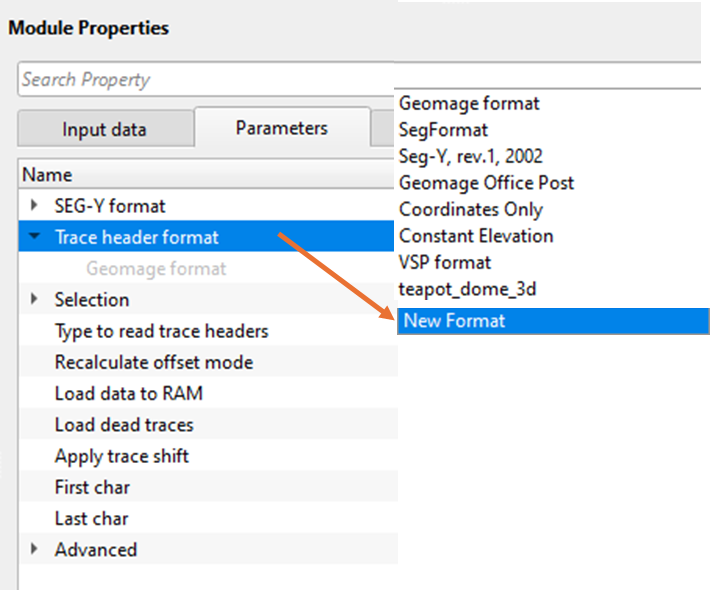
How to create new trace header format?
Geomage format is a standard SEG-Y Rev 1.0. This is the default trace header format inside the Read multi SEG-Y traces module. User can create a new trace header format as per the input data requirements.
•Go to Trace header format and click on Geomage format.
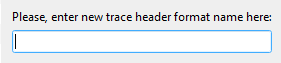
•At the bottom of the drop down menu, New format exists. Click on New format. Give it a name.
•Now the Trace header format changes from Geomage format to user defined format.
•Click on the calculator/table icon. It will open a window. Edit the trace headers as per the input data.
![]()
![]()
Clear input files - clears all the input files from the input file list
Clear output collections - clears all output collection files from the memory
Clear output selected collections - clears selected output file from the memory
![]()
![]()
YouTube video lesson, click here to open [VIDEO IN PROCESS...]
![]()
![]()
Yilmaz. O., 1987, Seismic data processing: Society of Exploration Geophysicist
 * * * If you have any questions, please send an e-mail to: support@geomage.com * * *
* * * If you have any questions, please send an e-mail to: support@geomage.com * * *
![]()